As part of my work at Sopra Steria, I have been asked to review several implementation of Artificial Intelligence models to help bring more efficiency and expertise in large databases. This paper, written by Jaewoong Kim and Moohong Min, is a great example of how AI can be used to help in the pharmaceutical industry. This article is a review of their work on the QA-RAG model. I am not affiliated with the authors or their institutions.
This research puts into perspective the interest professionals must have towards the implementation of the RAG model. Particularly, this document looks into one way of using RAG models to answer specific questions in very specific domains.
The QA-RAG, also known as Question-Answer Retrieval Augmented Generation, is a powerful mix of both NLP models and RAG models. This strategy helps combine a full-fledged and heterogeneous database with a chatbot designed to answer the questions of a user.
As it grows and evolves, a large volume of knowledge is required in specific domains such as science or finance. This knowledge must be up-to-date at any point, to enable end users to dispose of the information they need. Concurrently, a certain assurance in the production of answers is expected. Science fields such as pharmaceutical activities needs to possess a certain degree of precision to deliver the practices society expects.
efficiency: QA-RAG versus RAG versus Seq2seq
Jaewoong Kim and Moohong Min explain how "in knowledge-dense NLP tasks", "RAG models excel over typical seq2seq models". This problematic helps us lean towards the RAG models and enrich us into "retriev[ing]-and-extract[ing]" the data we need.
However, as much as RAG models have advanced to this day, the ultimate need in "regulatory compliance [...]" in specific domains that need this "highly specialized information" assurance.
De facto, the authors introduce a model that is directly built on the promise of the RAG model. The QA-RAG model is designed to fight against the limitations of both seq2seq and base RAG. The QA-RAG helps build a chatbot directly around the RAG architecture, rich of its accumulated data. Thus, the whole lot of information collected can be interacted with by the end user as they would with LLM such as ChatGPT.
Jaewoong and Moohong may describe the need for extreme precision the QA-RAG can bring, but do not specify whether the realization with their model is sine qua non. Furthermore, I would like to address the fact that this could still be performed with a classic RAG model, but the final choice of the model must be tailored to the use cases it will impact.
in-depth details on the QA-RAG model
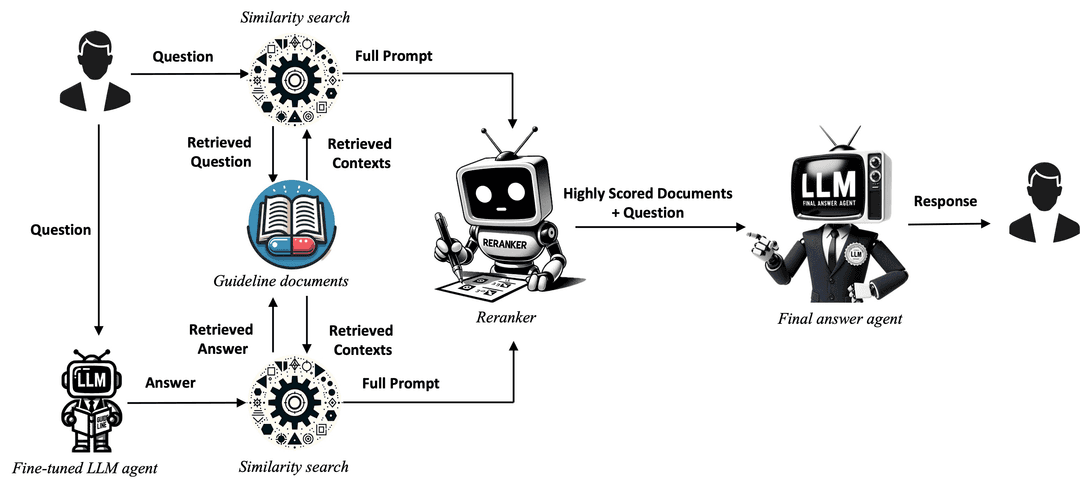
Figure 1: QA-RAG model diagram
first step: processing the user's question and selecting relevant documents
As it clearly stands out in the figure 1 above, the QA-RAG model requires as input two types of data:
- The user question
- Documents that the use case requires
When a user asks a question, it is redirected to two entities. The first one is a fine-tuned LLM agent. This agent reformulates the user's question into several prompts. The several prompts help encapsulate different perspective the question may raise and also helps define a clear structure out of the question given. This advanced technique is called multiquery retrieval.
The second one is the similarity search engine. This engine retrieves relevant documents.
To achieve a more thorough and nuanced retrieval of information, QA-RAG uses this "dual-track" approach. Thus, both the user's question and the prompts generated by the fined-tuned LLM agent are given to the similarity search engine.
second step: ranking the documents
The documents fetched thanks to the question and the generated prompts are passed to the reranker. Its job is to classify the documents into a ranking system based on their relevance. This scoring agent employs the BGE reranker model.
BGE stands for BAAI General Embedding. It originates from the Beijing Academy of Artificial Intelligence (BAAI). This popular reranker model is one out of many BGE models that embed texts.
On a ten-point scale, the documents are evaluated on their "contextual alignment" with the prompts.
The documents are noted as follows:
where for each .
Here is the BGE reranker evaluation. It evaluates each document in the retrieve documents pool and ranks each one's relevance to the query:
where
Finally, the ranking is represented as such:
is among the top scores
third step: transforming the documents into a final answer
The last step of this QA-RAG process is the generation of the answer thanks to the "final answer agent". This employs a LLM model such as ChatGPT-3.5-turbo.
The paper mentions: "The final response generation step of the QA-RAG model incorporates a sophisticated few-shot prompting technique [...] to enhance the accuracy of the answer. This technique [...] leverages a composition of an example question-answer set that is fed prior to the question."
Indeed, the last agent knows the form in which the answer has to be formulated.
one last step
This paper also outlines the importance of combining both question and a hypothetical answer. This hypothetical answer is generated by an LLM and helps in many ways the final answer agent to deliver better responses.
In order to implement this, simply provide alongside the question, a hypothetical answer; an answer that is acceptable but still requires all the data fact-checking and expertise the documents bring.
bibliography
- From RAG to QA-RAG: Integrating Generative AI for Pharmaceutical Regulatory Compliance Process
- GitHub - jwoongkim11/QA-RAG: Code for the paper, From RAG to QA-RAG: Integrating Generative AI for Pharmaceutical Regulatory Compliance Process
- HYDE: Revolutionising Search with Hypothetical Document Embeddings | by Mark Craddock | Prompt Engineering | Medium
- Se2seq